Thoughts on coding with LLMs
Cursor is one of a new wave of AI-first code editors (others include Zed), which intend to change the paradigm of programming using built-in AI features.
I installed Cursor and Zed last year when I was trying to brush up on the latest on coding with LLMs. I figured I should stay up to date with the latest tools, lest I get replaced by some junior developer who’s plugged an LLM into their brainstem while I’m still painstakingly writing my artisanal code by hand.
Back then, I found that the code suggestions generated by GPT-4 and especially GPT-3.5 just weren’t up to snuff. I had to spend way more time debugging and fixing the crappy generated code than it’d take for me to just write things out myself.
A few weeks ago, I decided to give Cursor another go, because of a series of videos that Sahil Lavingia had started putting out. A friend of mine said he’d totally changed his programming workflow after starting to use Cursor, so I figured I should give it another shot.
The bottom line: Cursor + Claude Sonnet are at a point where I’m starting to fundamentally change the workflow of how I write code. And I say this as an AI skeptic who’s been avoiding using these tools for the past 2-3 years because I’ve found them mostly distracting thus far.
I want to thank Sahil for putting out these Cursor videos to bring attention to this topic. My main issue is that the videos are way too long and digress to lots of other topics, which makes them difficult to grok.
I’m writing this blog post to make the ideas more accessible to people who prefer text over long videos, and to reflect on what this latest wave of AI tools means for the future of programming.
In this post, I...
- Describe the workflow of how I use Cursor
- Reflect on this new workflow, and what it means for the future of programming
- For anyone who’s interested, describe how to get started using Cursor
Programming workflow
Here’s the workflow I’ve converged towards while using Cursor:
- Conceptualize and articulate the change I want to make
- Build context for the LLM to make the change
- Generate code and accept the change
- Rerun code (if applicable) and validate the result
Throughout the examples below, I’ll be focusing on a personal project I’ve been working on recently: An interactive map of all the trees in major cities like NYC and SF. The code includes some light data transformation logic in Pandas, plus a React web app that uses Mapbox.
Conceptualize and articulate
When coding with Cursor, I’ve started pausing to reflect on exactly what I want at each step while implementing something. Previously, I might’ve skipped this step and just jumped into modifying code directly, but working with an LLM forces you to describe in clear language what you want to happen next. Doing this step of articulating what I want feels like a very iterative version of writing a product spec.
When describing what you want, it’s important to keep the changes incremental, and tune the complexity of your requests based on how boilerplate the code is. For example, if you’re writing very generic code (e.g. create a React component), you can just say “create react component”. If you want something more complex and unique, you may want to break the instructions into a few smaller pieces and describe each in greater detail. This allows you to get functioning, high-quality code on each step.
Build context
Cursor has simple but powerful tools for tuning exactly what the LLM sees in context. Besides advances in the underlying models, I think this improved context-tuning is what’s led to the greatest advances in coding with LLMs over the past year.
In Cursor, context can include:
@Fileand@Folderallow you to point at specific parts of your codebase.@Weballows the LLM to search for web sources.- Images, like mockups, can be uploaded to guide the LLM.
@Docsallows you to point to documentation on the web. Many sources are already indexed, but you can also index additional sources.
As an example, I needed to update some constants to center my map to San Francisco instead of New York City. Instead of Googling for lat/long coordinates to update my code, I just added @Web to my prompt and let the LLM find the appropriate values:
Generate code
Once your context and command is built, you can send the command to the LLM and have it generate code.
 This code ran perfectly on the first try.
This code ran perfectly on the first try.Run and validate
You could manually read and review all the code the LLM writes. Although this was my initial instinct because I was afraid of hallucinations, I’ve come to realize this isn’t fully embracing the power of these tools, which can generate largely correct code for a wide range of tasks.
Instead, you want to make it as fast and painless as possible to run the code and validate the results.
It’s usually easy to validate frontend code by rebuilding the frontend and manually inspecting the UI, which is why lots of AI coding demos focus on frontend logic. In my case, I was working on data transformation logic, which isn’t quite as trivial to validate. I ended up running code on small samples of the data to confirm that logic ran without errors, then outputted visual results that I could manually inspect.
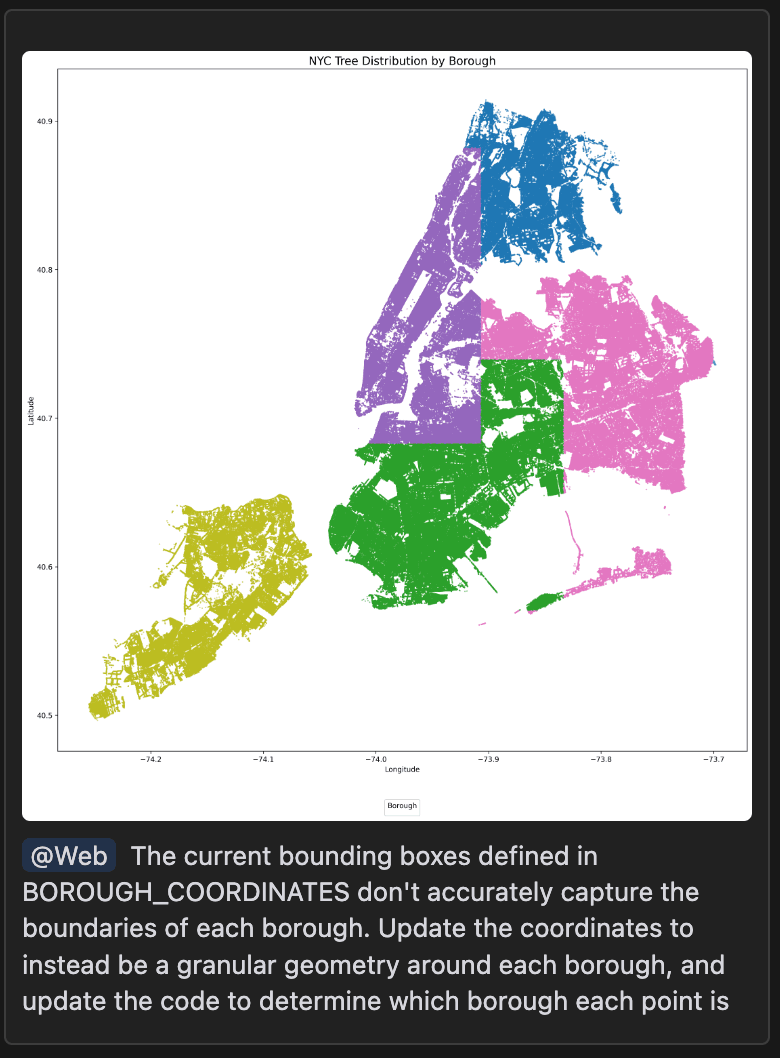
Looking at the results, it was obvious that the naive implementation of the borough-derivation logic was incorrect. But I was able to take a screenshot of the incorrect results, add that as context into the next prompt in conjunction with a @Web search, and get the LLM to mostly fix the issue.
In cases where you’re working on platform or framework code where it’s not possible to manually view the results, I think leveraging the LLM will require writing effective unit and integration tests that you can quickly run whenever code is added or modified. This makes it so that you can have a tight iteration cycle with the LLM, validating results without having to read every line of code.
Reflections and speculations
Although I’ve just been using Cursor in this way for a couple of weeks, I’ve pretty much fully switched over to using it for all my programming needs. And this switch is definitely the biggest change I’ve made to my programming workflow since I got started ten years ago.
What are the implications of all this? How will programming change in the future, if everyone starts to adopt these tools?
The most important skill is having good taste
In the age of generative AI, which human skills remain important for knowledge work? The primary answer I keep coming back to is good judgment, which in turn depends on having good taste.
For programming, the kind of taste you need is:
- Good taste for which problems are worth solving
- Good taste for what a good codebase and abstractions should look like
What features should the product have? How should they function? What level of performance is necessary? Although an LLM can help coach you about these questions, the space of possible solutions is infinite. Picking what to prioritize will remain the essential skill.
In software, good taste about the intermediate abstractions within your codebase and database also matter. These intermediates determine how nimbly you can adapt to emerging needs—no amount of LLM code generation will fix a horribly broken database schema. Having good taste for whether the internals of your codebase and database will remain essential, too.
Being able to quickly validate outputs is paramount
In developing software, there’s a sort of Maslow’s hierarchy of needs for what code should do:
- Is it correct?
- Is it performant?
- Is it secure?
- Is it well-structured?
In the past, a programmer would write the code themselves, validating these characteristics as they went. Now, I’m finding that since I’m no longer writing every line of code, I’m more focused on validating all of these characteristics than on the details of the code itself. If I’m convinced that all of these needs are fulfilled, I don’t really even need to read or understand the code!
Right now, the tools for validating LLM-written code feel manual and primitive. But I suspect that future workflows will incorporate LLMs to automatically validate the above characteristics of code, making it so that a single human programmer can command one LLM to write code, while a few other LLM-based processes validate the code’s behavior, performance, security, and cleanliness.
Right now, though, I find it helpful to keep the above “hierarchy of needs” in mind as I confirm the behavior of LLM-generated code.
Managing dependencies and running code are friction points
While coding with Cursor, my main frustrations were when I needed to step out of writing code and instead run code. I kept having to tweak scripts I was running to validate the behavior of my program. This was sort of OK, but whenever I needed to add a dependency, I had to update my environment to install the new dependencies, then rerun commands to get outputs working properly.
Even better tooling would be more aware of the context of my codebase and my current environment. Ideally, when code is modified, a suite of tests or commands could automatically be run to validate the resulting behavior. And if a file that affects my environment is modified—like a package.json file or pyproject.toml—then that ought to kick off a background process that automatically updates my environment without requiring me to explicitly run commands to do so.
Development will become more asynchronous
All the friction points I’ve outlined could be addressed through features that kick off background processes. These processes could automatically run tests, check for bugs or security issues, or suggest code style changes.
Cursor and other editors are already starting to ship features like this. There’s an experimental “AI Review” feature that tries to check your git diff for bugs, which I think is a good first step in this direction.
But I think the logical limit here is that a programmer will actually be commanding a small army of “coding agents” whenever they’re programming. There’ll be one primary agent that I’m commanding to write code, plus other background processes running to give me feedback on the code that’s been written.
I think this future workflow would make it faster to get to high-quality and correct code, but the downside might be that programming could end up feeling much more chaotic. In a sense, programming would feel like managing a small team. Even individual contributors will end up being managers of AIs.
I’ve always felt that software engineers—and the tools we create for ourselves—are years or decades ahead of the tools that the rest of the economy will eventually adopt. For example, you can see ideas like version control beginning to show up in other tools for knowledge work.
If I’m right about programmers becoming “managers of AIs,” then perhaps that’s what all knowledge work will start to look like in the coming years and decades.
If you found this post useful, please let me know! I always love to hear from folks online: vipul@vipshek.com. Also, consider subscribing for further writing from me, mostly about non-technical subjects.
Further reading on this topic:
- Coding with Cursor: Session 1
- Coding with Cursor: Session 2
- Coding with Cursor: Session 3
- Problems for 2024-2025 (Cursor)
- Building a Text Editor in the Times of AI (Zed)
Setting up and using Cursor
How do you actually get set up to use Cursor in the best way possible? Here’s my quick guide:
- Install Cursor
- Go to Cursor Settings (
Cmd/Ctrl + Shift + J) - Select Models in the sidebar, and turn off everything except
claude-3.5-sonnet - Select Beta in the sidebar, and toggle the dropdown under Composer to enabled. This enables the experimental multi-file-editing interface.
Next, you can run through the example Cursor has provided in ~/.cursor-tutor/projects/python/main.py or ~/.cursor-tutor/projects/javascript/src/index.js. I recommend going through these examples to learn the basics.
The main entrypoints I’d recommend learning are:
Cmd/Ctrl + Kto prompt writing code at the current location- Highlight code +
Cmd/Ctrl + Kto overwrite/modify a block of code Cmd/Ctrl + Lto ask questions about the codeCmd/Ctrl + Ito prompt writing code across multiple files
Just follow the instructions in the Cursor tutor files to create and iterate on a tic-tac-toe game, then start working on your own codebase.